I recently finished a project related to novelsphere.js with Purescript. I really like it.
I think safety comes from two levels. The first one is people’s desire to have a safe environment, a robust foundation to build things on. The second is they need the tools to create such environment in a sensible way. Purescript is safe because it has both.
In the functional community, people prefer to design data structures and functions to improve safety, or even making illegal states are unrepresentable. A simple example is an CSS font API that force me to provide a nonempty array of font-family. Or an API that utilises the type system to enforce some mutation does not escape a certain bound. If you only need the functionalities, the APIs don’t have to be in the above shape, it is always possible to ask for an array instead of a nonempty one, and you may be able to save a minute because you don’t have to learn how to create a nonempty array, but what do you get with that approach? The chance that it returns invalid output in runtime is not obvious until you see the error. In contrast, an API designed with safety in mind forces you to provide valid input, with the responsibility to make sure the list is not empty, the function guarantees the output must be valid CSS. I find the type system actually helps me to think, instead of constraining me. I cannot just write whatever crazy ideas come up in my head without clearing my mind, and that’s a good thing. It almost feels like, when it compiles, it works.
Before I learn Haskell and Purescript, I never realise how unsafe other languages I have been using are, probably because there was no contrast, and I never thought we can write codes that make that many explicit guarantees.
For example in Javascript you cannot really assure a function is taking or returning the correct types without explicitly checking every time, you can’t really make sure a function does not throw exception without looking at all the functions inside. That means some basic blocks in the foundation are not as robust as you may want it to be. Maybe you are standing on a Jenga tower.
a =
a + 1 == a + 1 // false
; // Can you assure `foo` is executed? no, because bar might throws.
You may say, but people don’t do crazy things like this! Well, that’s what you wish. In Purescript, that’s what you are guaranteed. In fact, changing the meaning of basic operators seems to be acceptable in some communities, which gives surprising behaviour. If there is a chance that c == c is not True, or not even a boolean, then how can you write code with confidence?
The next thing is having the tool to create a safe foundation. Even if you want to have a safe foundation and want to make guarantees, languages like Javascript and Python may not be able to help you. What’s missing in those languages? I think is the ability of “expressing abstract concepts accurately”. For example, in Python some APIs might expect a string or an iterator of string, but string itself is an iterator of characters, so there can be two ways to interpret the string and both of them can be arguably correct. In Javascript, there are objects that are array-like, but how exactly are they different from array? The answer is hidden in implementation details. NodeList is an Array-like, you can call nodeList[2], nodeList.length or nodeList.forEach, but not nodeList.map. arguments is an Array-like too, arguments[0] and arguments.length works, but not arguments.forEach. Now try to guess if you can call fileList.forEach? It’s famous that dynamic languages think If it walks like a duck and it quacks like a duck, then it must be a duck. The problem though is, if you need a duck, you should ask for a duck. If you have something that only quacks, don’t claim you have a duck, you have “something that quacks”. The inability of expressing “quacker” in type level is what causing the trouble.People usually specify the behaviour with documentations, but it seldom makes anything better. Saying something is array-like makes no guarentee on the value, It’s hard to verify and you might break codes easily. It is like achieving flexibility by ambiguity.
On the other hand, the powerful type system in Purescript allows people to express abstract concepts, type classes accurately specify the expectation on type, and people usually utilising the type system to write safer code even when it is not compulsory. While it seems harder to learn, it is capable to model lots of abstract concept, and it helps to “enforce” your program to be more correct. You don’t get NullPointerException or “undefined is not a function”. For many times I find myself stopped in the middle of implementing some functions, because the type signature forces me to have a certain type which I don’t have. The type system force me to be clear about what I have to write.
With everything strongly typed, one might expect codes to be inflexible because it feels like “bounded” by the types. It is surprisingly not the case! I changed my mind many times about the types of some functions, but making changes is surprisingly smooth and easy.
Lets say I have a simple operation that calculate the score of a string (perhaps measuring how secure a password is?), this operation might fail for whatever reason. Though, all I care about is the result, in case of error, I will just let the error propagate to somewhere else. A normal usage of such function would look like this.
In Purescript it looks like this.
calculateScore input = handleScore <$> calculate input
Then, I changed my mind, there are actually a lot of reasons to fail, I need specific error messages. So I updated the code to produce an error message. In JavaScript you might do it in these ways.
// Well, you can omit the try / catch block because we just rethrow the error.
// But then users would not realise this function might throw
}
In Purescript, it looks like this.
calculateScore input = handleScore <$> calculate input
Unfortunately, I changed my mind again! I just find out the calculation is better done at the server side for whatever reason. Well, that’s a pretty big change, now the operation is async, the program would probably looks like this.
Or, if you are using promise, it would look like this.
In Purescript, as you may guessed, looks like this, again.
calculateScore input = handleScore <$> calculate input
Those JavaScript codes look pretty different! Changing the types means changing the code that use the types, and of course that involve every caller that call those functions, what a big change! But what’s happening in Purescript? In Purescript, there is something called “type class”, and one of the type classes is called Functor, it represents a rather abstract concept. That is the secret behind the magical <$> sign. It allows me to write the code for different types. In the above example the <$> operator basically says When the right hand side (calculate input) has a value, process it with the left hand side (handleScore). It does not care about where do you get the value, do you have error message or not, or is it synchronise or not. The same code can also be used to handle a list, a map, a signal, or even a function. By using this operator, the code is actually making very few assumption on the calculate function. The least assumption there are, the less likely it is going to break. By having abstract concepts like this, codes actually get more flexible and reusable.
When I was making purescript-pux-form, I changed my mind few times on the representation of the field list, but it is super easy to refactor once I decided to change.
Coming from Javascript to Purescript is a big leap. In the beginning I worried what if I cannot understand this language? Is there any escape route? What if there is no library, is it easy for beginners like me to create one? The answer is, there is nothing to worry about. Purescipt’s FFI to JavaScript is straight forward and yet very flexible. Wrapping around side effects is easy and the compiled Javascript is still readable. Of course it is not going to be as straight forward as writing a Typescript type definition file, but it is not supposed to be!
People in the Purescript community are super helpful, it’s the best community I have ever seen. The community may be small, but it’s active and friendly. If anyone has any question please feel free to ask on the functional programming slack! Oh and the quality of packages are usually quite good!
Under the hood it is still Javascript, so there are cases that I cannot convert perfectly into Purescript’s model. For example I was dealing with some drag and drop related events. It turns out drag event’s file list is “live”, it is representing the actual underlying data instead of an immutable one that Purescript prefers. According to the spec, the file list might turn into protected mode without anyone touching it.
;
Of course I can structure the code to consume the file list immediately in the event handler, but that is like hiding an assumption in code. The timing of consumption will be an implicit expectation, which is bad. I end up creating a hackDragEvent functions that returns a proxy of the event with its file list cloned. It’s not beautiful, but the existence of such function should act as a warning to whoever reads the code later.
Yes, definitely. I spend much longer time on Purescript than other languages, but I’d say it absolutely worths.
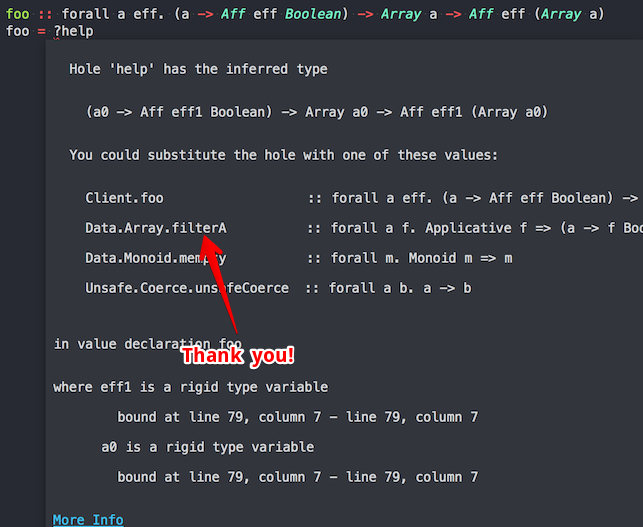
You don’t have to learn everything. It’s tricky to learn what do you have to learn, but once you get it, it’s easy to move on. I once had to filter a list, but the filter operation is not simple, I have to read files from the file system in order to determine whether to filter or not, so it’s an asynchronous operation with side effects. When I was wondering how to filter the list, I used the very convenient typed hole function from the compiler. It suggested me the filterA function.
I didn’t really know how is it exactly implemented, but it asks for an Applicative, and the asynchronous operation turns out to be an Applicative. I thought, well the type matches, so lets have a try, and it worked! I then read through the documentation and discovered a function call parallel which returns a “parallelised” version of the operation. It has to do with some other concepts that I didn’t understand, but anyway the types match, and it worked.
Knowledge is reusable as well. I might need to spend time learning the basics in the beginning, but many concepts are related to each other. The more I learn, the easier it is to catch up on other ideas. It worths mention that those concepts are not random concepts invented (and reinvented) like what’s happening in the JS community. Functional programming concepts are usually backed by theories and laws, I find them more generic and profound (though I never read those papers).
If you want to learn more about Purescript, here are some useful resources.