I was chatting with friends about types. It seems that “type” means so many different things in different programming languages, “type safe” does not really mean anything without context. So here is this blog post, of me trying to explain what do I think about types, and how it helps us to program.
What is type? I would refer it to a collection of possible values.
Say for example you have a function that measure the length of a string, the type is simply String -> Integer. The type tells you, as long as you give the function a string, it returns an integer. Any valid string is a valid input of the function, and it’s output is going to be a valid integer. This is well-typed because as long as you match the types, it cannot go wrong. But is this always true?
Lets look at a very simple function. This is a NSNotificationCenter’s method that registers a handler for some kind of notifications. What’s interesting is the type of an argument, NSNotificationName, which, according to the document:
In Objective-C, NSNotification names are type aliased to the NSString class. In Swift, Notification names use the nested NSNotificationName type.
That means in Objective-C you can pass a string as an argument, if you make a typo, the compiler wouldn’t realise, but it just doesn’t work. In Swift though, all the available notification names are known statically, if you make a typo, the compiler would shout at you with an error message, probably something like unknown identifier.
There isn’t any rocket science here, ultimately the same thing can be achieved in Objective-C as well (whether is it practical is another question). The point is, by switching from the string type to the NSNotificationName type, users are now required to pass a value from a much smaller collection of possible value. It worths noting that, even in Swift NSNotificationName is still backed by String. The type does not only represent the data’s binary representation, but an application-level knowledge. Users might pass a wrong value, but it’s always a valid one. The type is now more accurate, if the type matches, you are guaranteed to have registered to some notifications. Now it’s safer.
You may think, of course it’s better to have everything modelled in their own types, but if we have to create a type just for an argument, does that mean we have to create tons of types, just to make our program a little safer? That seems unmaintainable and time consuming!
There are at least two solutions: Codegen and type level programming.
The idea of codegen is simple. Generate codes automatically instead of writing them. At HERP, we generate quite some codes for both our client and server side, just to make sure we don’t make mistake when crossing the network boundary. Our API is defined with Swagger, then a few things are generated:
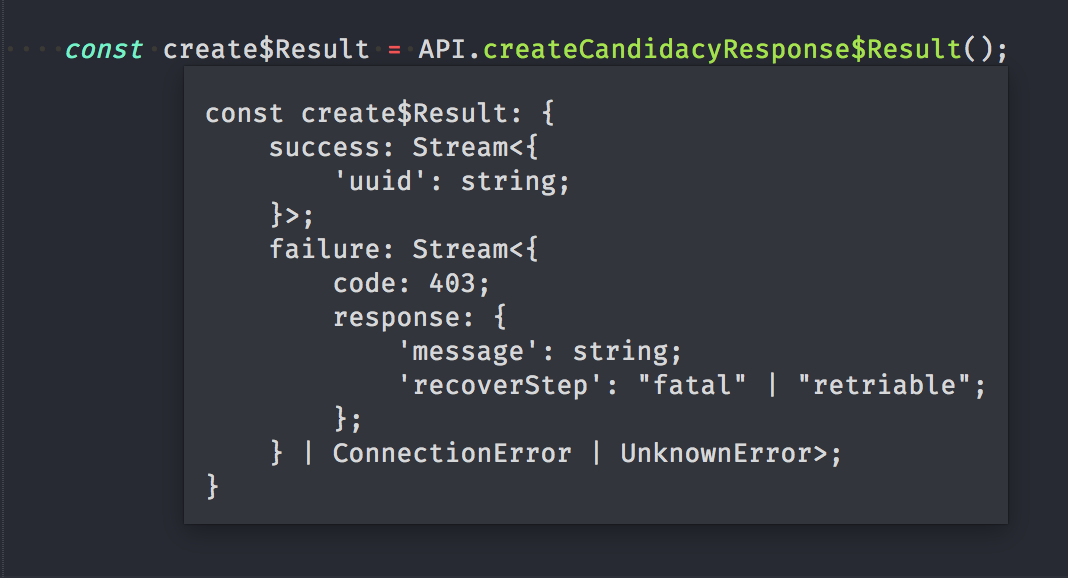
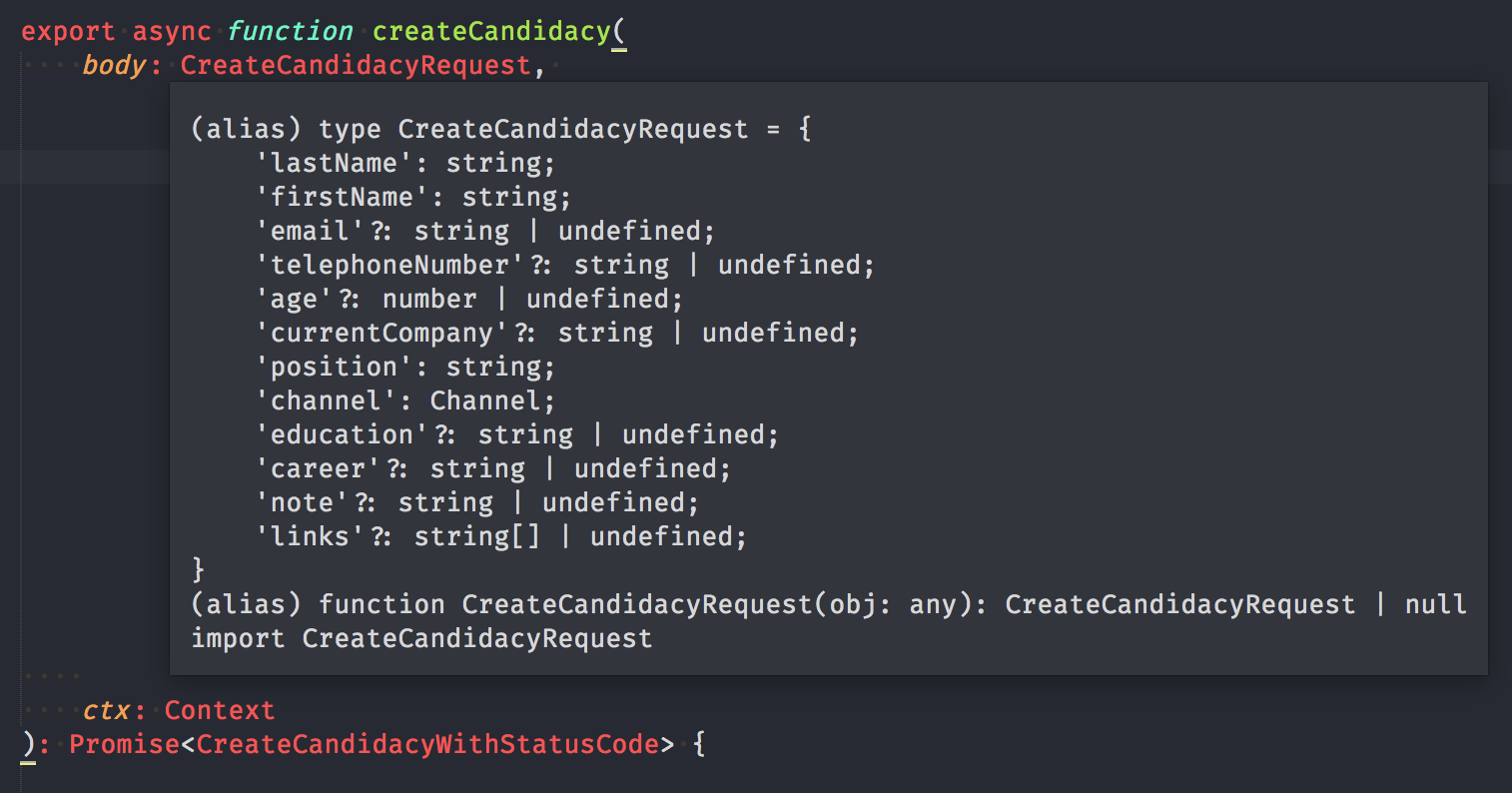
In TypeScript, request type, response types, and a function are generated for each endpoint. Which means it’s not possible to send a malformed request, possible errors are explicitly described in the response type to facilitate error handling, this is also true for server side.
If I make a mistake returning an unexpected response to the client side, the type checker will stop me!
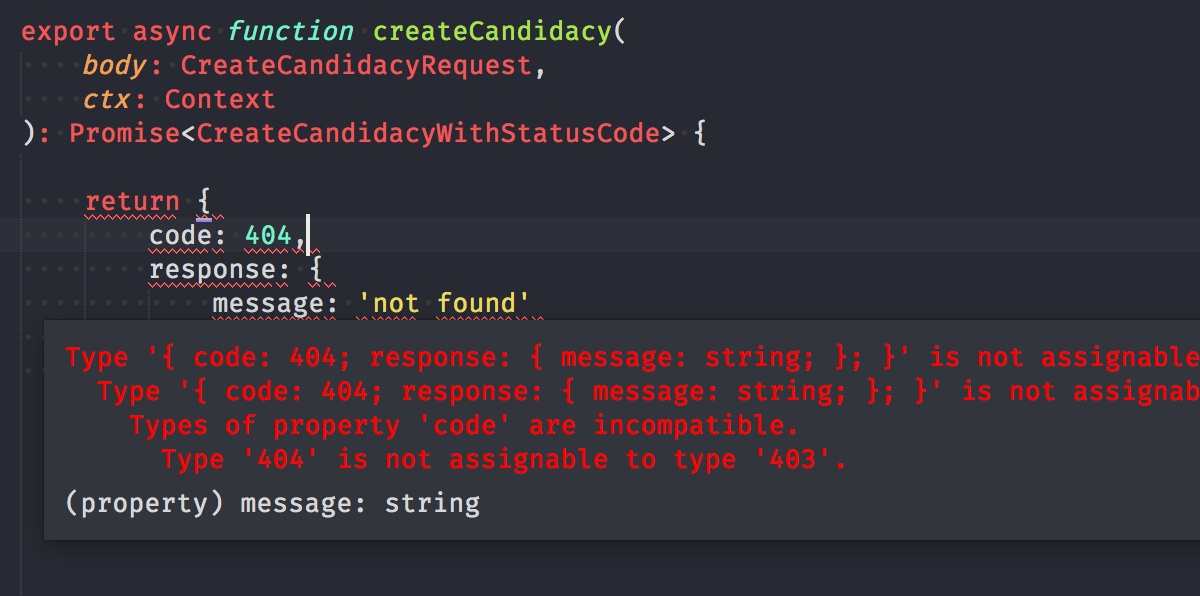
Now that’s safer than the default type definition :)
Codegen is also very useful when you are working with a language that avoids generics, but you really want generics.
While codegen is powerful, it does not feel elegent to me. Listing out every possible type feels brute force for me, as a programmer, why can’t I calculate the types instead? With a strong-enough type system, logics can be expressed in types, and the type checker solves the logic. Type level programming allows programmers to write compile-time code to check their code. For instance here is a type-safe printf written in Purescript, or a type-safe regular expression library in Haskell1. At HERP, we use type level programming to express relationships between data, and ensure permission checking for database access. It makes us possible to express business logic at compile time and therefore avoid mistakes.
It’s true that not every language’s type system is strong enough to do this kind of programming, but sometimes they are more powerful than expected. Even if it’s weak, you can still try to poke around the types to see what you can do! For example here is a library for some basic type level programming in TypeScript.
Type, from the simple definition to the complicated type level programming stuffs, is a very large topic. There are lots of theories and papers around the idea, but they are all about one thing, making code safer. Though, it’s after all just a tool, if you don’t utilise it, your code is not going to be any safer. Changing the type signature from .js to .ts does not all of a sudden make anything better. If anyone comes from a dynamically-typed background who would try to give statically-typed a try, my suggestion is:
any (or Object in Java, interface{} in Go) as much as possible. There is no type information from the type, you are going back to dynamic.Sometimes I see people code in a way as if they are fighting against the type system, it’s a pity to see a great tool for writing safer code is being wasted. At least from my personal experience, when you try to embrace the types, the type-checker guides you back. Nowadays when I write Haskell, the list of type errors is simply my task list. When it compiles, it works.